
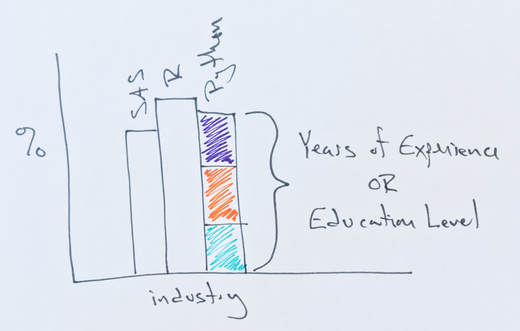
 New plot with industry on the X-axis and percent of responses on the Y-axis. Each industry has three bars representing the three analysis tools or the three years-of-experience or three education levels.
New plot with industry on the X-axis and percent of responses on the Y-axis. Each industry has three bars representing the three analysis tools or the three years-of-experience or three education levels.
Burtch Works released the results of their 2018 SAS, R, or Python Survey Results: Which do Data Scientists & Analytics Pros Prefer? survey (also available on YouTube). The results are provided to help those seeking a job in the data science or predictive modeling and analysis fields to understand better which data analysis tool is most popular in the different areas. The survey asks respondents to provide information about their professional career; preferred data analysis tool, highest degree, industry, and region of the United States. They have been performing the survey since 2014, but in 2016 they added Python to the initial list of preferred data analysis tool; SAS or R. While I found their survey interesting, it left me with the following questions.
Why has Python’s popularity increased?
The Burtch Works’ presentation does not explore the increased popularity of Python. One possible reason: Python is a general programming language, while SAS and R are considered specialized tools for the statistical analysis of data. Thus, Python is a flexible programming language able to create standalone applications -- e.g., web applications and games to name a few -- whereas SAS and R are statistical analysis languages first. It is Python’s flexibility that has allowed the addition of data collection and analysis packages.
Another likely reason for the increase in Python’s popularity within this survey, Python is a common first programming course for (computer) science majors. Thus, students learn Python, use it throughout their education, and then continue using it in their career. It does not matter if they go on to write software or become data scientists. They have been using Python for at least four years when they graduate and Python has the ability to adequately fill so many computer science roles -- from applied applications in the business world to scientific fields such as computational chemistry (see OpenEye Scientific Software, Schrodinger, and PyMOL) to other academic research fields -- no other programming language needed. Additionally, Python is open source (like R) easily links to a GUI toolkit, and can use numerous third-party packages (also like R). It is very understandable why it is a favorite and accessible programming language to learn and continually grow.
Why is SAS dominant in specific industries?
SAS is dominant in the Financial Services, Healthcare, and the Pharmaceutical industry. Compared to the other represented industries (Technology & Telecommunications, Consulting, Advertising & Marketing, and Retail), it is understandable SAS’ domination in these three areas. The Financial, Healthcare, and Pharmaceutical industries have long relied on the data analysis to create products and make better decisions. An often overlooked aspect of selecting a software platform is user support. SAS provides clients the ability to talk with a SAS expert, receive SAS training, and get relatively quick answers to questions about SAS from SAS. These features -- often not initially thought of -- are huge benefits when selecting a software package. Another possible reason for SAS’ low use-rate in other industries is that these industries have recently started to adopt these tools to analyze their data and aid their decisions.
More plots?
The survey results demonstrate SAS' popularity in three industries with a long history of using data analytics. However, modifying the “SAS, R, or Python Preference by Industry” plot to have each bar segmented by years-of-experience or education level would increase the information conveyed to the reader.
Segmenting the SAS, R, or Python bars into the three years-of-experience ranges shows the relationship between years-of-experience and preference for a specific tool within each industry. Changing the segments from years-of-experience to education level focuses on the relationship between tool choice and education. To gain insight to the education and experience trends within each industry, have the bars represent each education level -- in each industry -- and then segment each bar into the three years-of-experience ranges. The additional plots add insight into the likelihood of a change in tool preference, hiring trends related to education, and the relationship between experience and education towards tool preference.
Why has Python’s popularity increased?
The Burtch Works’ presentation does not explore the increased popularity of Python. One possible reason: Python is a general programming language, while SAS and R are considered specialized tools for the statistical analysis of data. Thus, Python is a flexible programming language able to create standalone applications -- e.g., web applications and games to name a few -- whereas SAS and R are statistical analysis languages first. It is Python’s flexibility that has allowed the addition of data collection and analysis packages.
Another likely reason for the increase in Python’s popularity within this survey, Python is a common first programming course for (computer) science majors. Thus, students learn Python, use it throughout their education, and then continue using it in their career. It does not matter if they go on to write software or become data scientists. They have been using Python for at least four years when they graduate and Python has the ability to adequately fill so many computer science roles -- from applied applications in the business world to scientific fields such as computational chemistry (see OpenEye Scientific Software, Schrodinger, and PyMOL) to other academic research fields -- no other programming language needed. Additionally, Python is open source (like R) easily links to a GUI toolkit, and can use numerous third-party packages (also like R). It is very understandable why it is a favorite and accessible programming language to learn and continually grow.
Why is SAS dominant in specific industries?
SAS is dominant in the Financial Services, Healthcare, and the Pharmaceutical industry. Compared to the other represented industries (Technology & Telecommunications, Consulting, Advertising & Marketing, and Retail), it is understandable SAS’ domination in these three areas. The Financial, Healthcare, and Pharmaceutical industries have long relied on the data analysis to create products and make better decisions. An often overlooked aspect of selecting a software platform is user support. SAS provides clients the ability to talk with a SAS expert, receive SAS training, and get relatively quick answers to questions about SAS from SAS. These features -- often not initially thought of -- are huge benefits when selecting a software package. Another possible reason for SAS’ low use-rate in other industries is that these industries have recently started to adopt these tools to analyze their data and aid their decisions.
More plots?
The survey results demonstrate SAS' popularity in three industries with a long history of using data analytics. However, modifying the “SAS, R, or Python Preference by Industry” plot to have each bar segmented by years-of-experience or education level would increase the information conveyed to the reader.
Segmenting the SAS, R, or Python bars into the three years-of-experience ranges shows the relationship between years-of-experience and preference for a specific tool within each industry. Changing the segments from years-of-experience to education level focuses on the relationship between tool choice and education. To gain insight to the education and experience trends within each industry, have the bars represent each education level -- in each industry -- and then segment each bar into the three years-of-experience ranges. The additional plots add insight into the likelihood of a change in tool preference, hiring trends related to education, and the relationship between experience and education towards tool preference.


 RSS Feed
RSS Feed